Этот материал — адаптированный перевод руководства от команды Spheron Network.
В середине 2025 года мейджор-лейблы завалили исками за нарушение авторских прав гигантов ИИ-музыки, Suno и Udio. И это заставило индустрию задуматься. Если платформу, на которой завязан ваш творческий процесс, могут в любой момент засудить или закрыть, что будет с вашим контентом?
Ответом стал уход в «свободное плавание» — развертывание open-source моделей на собственных серверах (self-hosted). Никаких внезапных блокировок, полные коммерческие права и независимость.
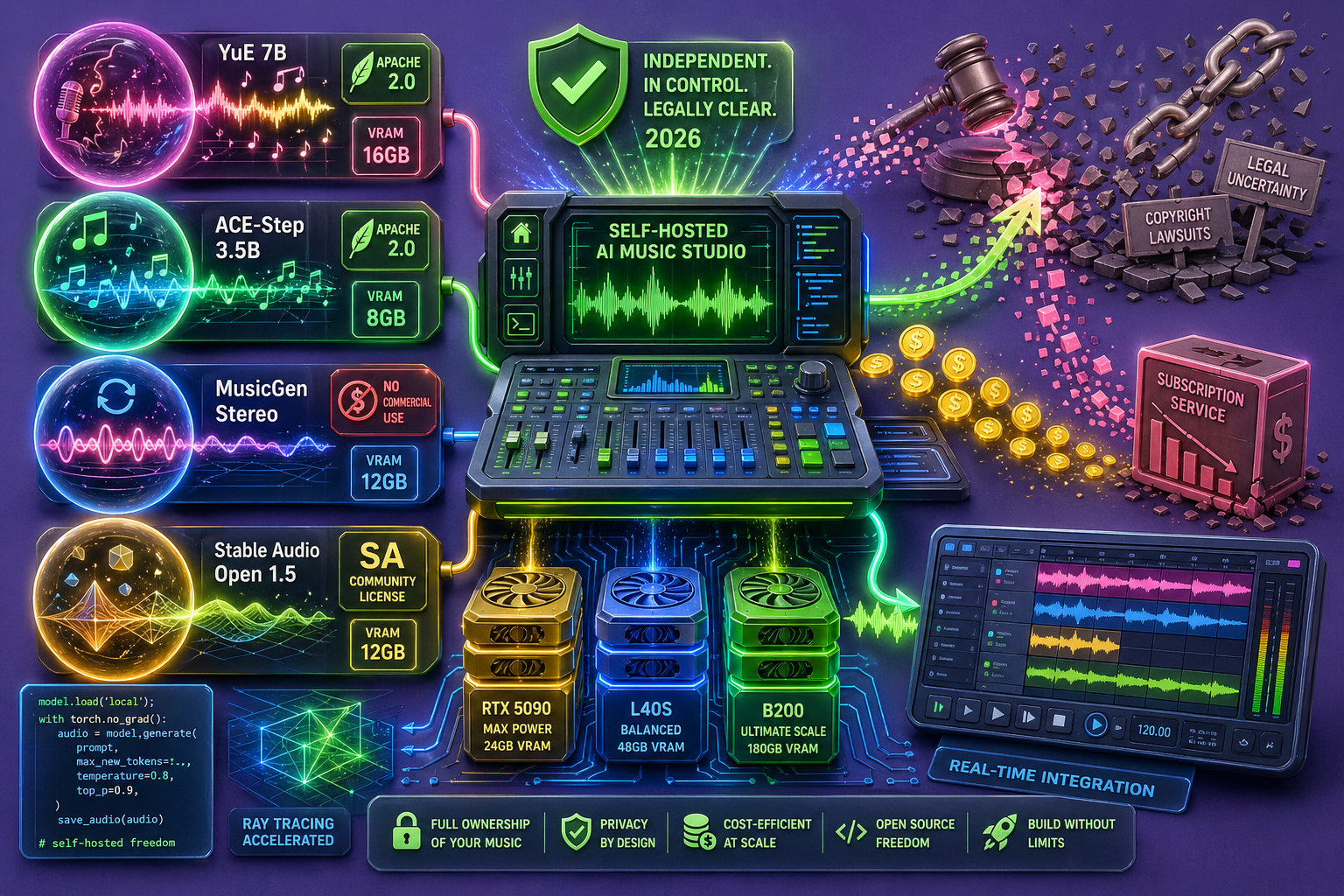
В этом гайде мы разберем четыре нейросети, которые стоит использовать в 2026 году: YuE 7B, ACE-Step 3.5B, MusicGen Stereo и Stable Audio Open 1.5. Расскажем, какое «железо» для них нужно, дадим готовый код для запуска и посчитаем, сколько реально стоит сгенерировать один трек.
🎹 Какую нейросеть выбрать для продакшена?
Сегодня на рынке есть четыре главных игрока. У каждого своя суперспособность и свои аппетиты к видеопамяти (VRAM).
- YuE 7B. Это самая продвинутая модель от команды Multimodal Art Projection. Модель генерирует полноценные песни с вокалом, строго следуя вашему тексту. Выдает стерео в качестве 44.1 кГц. Треки получаются длинными, по 3-4 минуты.
Подводные камни: прожорлива, нужно минимум 16 ГБ видеопамяти. Но зато у неё лицензия Apache 2.0 — генерируйте и монетизируйте треки легально. - ACE-Step 3.5B. В отличие от YuE, эта модель работает на диффузионной архитектуре (как генераторы картинок). Что это дает? Она быстрее генерирует звук и лучше слушается ваших подсказок по стилю.
Плюсы: влезает даже на обычную игровую видеокарту (нужно всего 8 ГБ VRAM). Лицензия тоже свободная (Apache 2.0). - MusicGen Stereo. Отлично справляется с фоновой музыкой по текстовому описанию.
Подводные камни: выдает только кусочки по 30 секунд (их нужно склеивать), требует 12 ГБ VRAM. Но главное — строгий запрет на коммерческое использование (лицензия CC BY-NC 4.0). Подойдет только для тестов или домашних проектов. - Stable Audio Open 1.5. Это инструмент не для песен, а саунд-дизайна.
Плюсы: идеальна для создания SFX, эмбиента и нестандартных звуковых текстур. Лимит длины — 47 секунд. Лицензия позволяет коммерцию, но с ограничениями по доходу компании (читайте правила перед релизом).
Сводная таблица моделей:
| Модель | Параметры | VRAM | Макс. длительность | Качество | Лицензия | Идеально для |
|---|---|---|---|---|---|---|
| YuE | 7B | 16 ГБ | 3-4 мин | 44.1 кГц | Apache 2.0 | Песни с вокалом и текстом |
| ACE-Step | 3.5B | 8 ГБ | Настраивается | 44.1 кГц | Apache 2.0 | Быстрые тесты, контроль стиля |
| MusicGen Stereo | 3.3B | 12 ГБ | ~30 секунд | 32 кГц | CC BY-NC 4.0 | Фоновая музыка, лупы |
| Stable Audio | ~1.1B | 12 ГБ | 47 секунд | 44.1 кГц | SA Community | Саунд-дизайн, SFX |
💻 Выбираем «железо»: от домашней студии до конвейера треков
Для запуска этих нейросетей нужны облачные GPU. Вот три варианта под разные задачи (цены средние по рынку):
- RTX 5090 (32 ГБ, ~$0.86/час). Базовый уровень. Потянет один поток тяжелой YuE или несколько потоков ACE-Step, MusicGen. Идеально для разработчиков, которые только тестируют свои ИИ-инструменты.
- L40S (48 ГБ, ~$0.32/час на Spot-тарифах). Рабочая лошадка для студий. Сюда влезут сразу три параллельных генерации YuE. Если вы делаете по 100-500 треков в день, это лучший выбор по соотношению цена/скорость.
- B200 (192 ГБ, ~$2.06/час на Spot). Промышленный масштаб. Тянет 12+ параллельных потоков YuE. При полной загрузке генерировать треки здесь даже дешевле, чем на L40S.
| GPU | VRAM | Потоки YuE | Потоки ACE-Step | Потоки MusicGen |
|---|---|---|---|---|
| RTX 5090 | 32 ГБ | 1 | 4 | 2 |
| L40S | 48 ГБ | 2-3 | 5-6 | 3-4 |
| H200 SXM | 141 ГБ | 8+ | 16+ | 11+ |
| B200 | 192 ГБ | 11+ | 22+ | 15+ |
🛠 Как это выглядит на практике
Для тех, кто готов поработать с кодом, вот готовые скрипты для запуска моделей.
1. Запускаем мощную YuE 7B
Сначала скачиваем модель и ставим зависимости:
git clone https://github.com/multimodal-art-projection/YuE
cd YuE
pip install -r requirements.txt
huggingface-cli download m-a-p/YuE-s1-7B-anneal-en-cot --local-dir checkpoints/yue-7b
Теперь запускаем саму генерацию. Небольшой лайфхак: если включить torch.compile, процесс пойдет на 15-20% быстрее.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "m-a-p/YuE-s1-7B-anneal-en-cot"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto"
)
# Ускоряем работу ИИ
model = torch.compile(model)
# Дальше идет ваша логика генерации трека...
2. Запускаем шуструю ACE-Step
Тут все проще, используем библиотеку diffusers. Важно: при массовой генерации не забывайте чистить кэш памяти (torch.cuda.empty_cache()), иначе сервер быстро «упадет» от перегрузки.
import torch
from diffusers import ACEStepPipeline
pipe = ACEStepPipeline.from_pretrained(
"ACE-Step/ACE-Step-v1-3.5B",
torch_dtype=torch.float16
).to("cuda")
# Генерируем несколько треков подряд
with torch.no_grad():
for i, prompt in enumerate(prompts):
audio = pipe(prompt=prompt, duration=30.0).audios[0]
save_audio(audio, f"output_{i}.wav")
torch.cuda.empty_cache() # Чистим память!
3. Базовый запуск MusicGen Stereo
from transformers import AutoProcessor, MusicgenForConditionalGeneration
import scipy
processor = AutoProcessor.from_pretrained("facebook/musicgen-stereo-large")
model = MusicgenForConditionalGeneration.from_pretrained(
"facebook/musicgen-stereo-large"
).to("cuda")
inputs = processor(
text=["ambient piano background, cinematic, slow"],
padding=True,
return_tensors="pt",
).to("cuda")
# 1500 токенов дадут нам примерно 30 секунд аудио
audio_values = model.generate(**inputs, max_new_tokens=1500)
scipy.io.wavfile.write(
"output.wav",
rate=model.config.audio_encoder.sampling_rate,
data=audio_values[0].cpu().numpy().T
)
✂️ Лайфхак: как склеить длинный трек (скользящее окно)
MusicGen выдает только отрезки по 30 секунд. Если просить больше, звук начнет «плыть». Решение? Делаем внахлест: генерируем 30 секунд, берем последние 10 секунд и просим ИИ продолжить с этого места. Вот код, который автоматизирует эту склейку:
import numpy as np
import soundfile as sf
import torch
SAMPLE_RATE = 32000
OVERLAP_SECONDS = 10
SEGMENT_TOKENS = 1500 # ~30 секунд
target_duration_seconds = 120 # Хотим трек на 2 минуты
num_segments = max(1, round((target_duration_seconds - OVERLAP_SECONDS) / (30 - OVERLAP_SECONDS)))
segments = []
conditioning = None
for i in range(num_segments):
if conditioning is not None:
inputs = processor(
text=[prompt], audio=conditioning, sampling_rate=SAMPLE_RATE,
padding=True, return_tensors="pt"
).to("cuda")
else:
inputs = processor(text=[prompt], padding=True, return_tensors="pt").to("cuda")
with torch.no_grad():
output = model.generate(**inputs, max_new_tokens=SEGMENT_TOKENS)
audio = output[0].cpu().numpy().T
overlap_samples = OVERLAP_SECONDS * SAMPLE_RATE
if i > 0:
audio = audio[overlap_samples:] # Обрезаем нахлест
segments.append(audio)
conditioning = output[0].cpu().numpy()[:, -overlap_samples:]
# Склеиваем всё в один большой трек
full_track = np.concatenate(segments)
sf.write("long_track.wav", full_track, SAMPLE_RATE)
🏭 Массовое производство: как генерировать тысячи треков
Если вы делаете ИИ-сервис или наполняете библиотеку, вам нужен фреймворк Ray. Он распределяет задачи по очередям, чтобы видеокарта не простаивала. С картой H200 один поток MusicGen может выдавать 600-900 отрезков (по 30 секунд) в час. Арендовав три карты L40S, вы пробьете планку в 1000 треков в час.
Код для создания таких независимых ИИ-воркеров:
import ray
from diffusers import ACEStepPipeline
import torch
ray.init()
@ray.remote(num_gpus=0.25) # Отдаем воркеру четверть видеокарты
class MusicWorker:
def __init__(self, model_id):
self.pipe = ACEStepPipeline.from_pretrained(
model_id, torch_dtype=torch.float16
).to("cuda")
def generate(self, prompt, duration):
with torch.no_grad():
audio = self.pipe(prompt=prompt, duration=duration).audios[0]
torch.cuda.empty_cache()
return audio
# Разворачиваем 4 воркера на одной L40S (они займут ~32 ГБ из 48 ГБ)
workers = [MusicWorker.remote("ACE-Step/ACE-Step-v1-3.5B") for _ in range(4)]
# Раскидываем задачи
futures = [
workers[i % len(workers)].generate.remote(prompt, 30.0)
for i, prompt in enumerate(prompts)
]
results = ray.get(futures)
🎛 Как подружить ИИ с вашей DAW (Ableton, FL Studio, Reaper)
Модели вроде YuE генерируют песню целиком. Вы сидите и ждете результата. А вот ACE-Step умеет отдавать звук кусками: первые 10 секунд уже играют, пока рендерится продолжение. Это идеально для работы прямо внутри секвенсора.
Как это реализовать. Поднимаете FastAPI-сервер на вашем облачном GPU и связываете его с DAW по протоколу OSC (подойдут костыли вроде Max4Live или скрипты Reaper).
Пример такого сервера:
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from diffusers import ACEStepPipeline
import torch, io
import soundfile as sf
app = FastAPI()
pipe = ACEStepPipeline.from_pretrained("ACE-Step/ACE-Step-v1-3.5B", torch_dtype=torch.float16).to("cuda")
@app.post("/generate")
def generate(prompt: str, duration: float = 10.0):
with torch.no_grad():
audio = pipe(prompt=prompt, duration=duration).audios[0]
torch.cuda.empty_cache()
buf = io.BytesIO()
sf.write(buf, audio.T, 44100, format="WAV")
buf.seek(0)
return StreamingResponse(buf, media_type="audio/wav") # Отдаем аудио потоком
Если запросить у сервера превью на 5 секунд, то на карте L40S вы получите готовый звук уже через 2-10 секунд. Отличная скорость для студийной импровизации!
⚖️ Юридическое минное поле: авторские права
Дисклеймер: мы не юристы, перед запуском стартапа обязательно проконсультируйтесь со специалистами.
Главное правило: размещение ИИ на своих серверах не делает музыку легальной автоматически. Все зависит от того, на чем обучалась модель и какая у нее лицензия.
- YuE и ACE-Step. Лицензия Apache 2.0. Вы можете использовать результаты в коммерции.
- Stable Audio Open 1.5. Допускает коммерцию, но есть ограничения по выручке вашего проекта.
- MusicGen. Обучена на закрытой библиотеке Meta*. Коммерческое использование вывода строго запрещено (CC BY-NC 4.0). Заработаете на этих треках — ждите судебный иск от корпорации.
Если не хотите рисковать — выбирайте модели на Apache 2.0 (YuE или ACE-Step).
💰 Считаем деньги: свой сервер vs подписка Suno
Для расчетов возьмем дешевые спотовые (Spot) тарифы на облачные видеокарты. L40S обойдется вам примерно в $0.32/час.
- YuE 7B делает 3-минутный трек примерно за 5 минут работы сервера.
Цена: $0.027 за песню. - ACE-Step рендерит 30 секунд за 2 минуты.
Цена: $0.011 за песню.
А теперь сравним с Suno Pro. Подписка стоит $96/год (дает 500 песен в месяц). Если выжмете лимит, одна песня обойдется вам в $0.016.
Вывод. Если вы генерируете пару сотен треков в месяц для себя, подписка Suno обойдется дешевле ($0.016 против $0.027 у своего сервера YuE).
Тогда зачем все эти заморочки с серверами?
Ответ: коммерческие права и масштабирование.
На бесплатных и базовых тарифах коммерция ограничена, а правила платформы могут поменяться в любой момент. Подняв свой сервер, вы получаете неограниченный безлимит, 100% владение правами на сгенерированный звук и полную независимость от корпоративных судов. А на промышленных масштабах (тысячи треков) свой сервер становится кратно дешевле любой подписки.
Примечание: * Meta признана в РФ экстремистской организацией, ее деятельность запрещена.
📈 Бонус: настраиваем автомасштабирование (Ray Serve)
Если ваш ИИ-сервис вдруг стал вирусным, один сервер не справится. Вот как заставить фреймворк Ray автоматически докупать сервера при наплыве юзеров и отключать их ночью.
from ray import serve
# Настраиваем логику масштабирования
@serve.deployment(
autoscaling_config={
"min_replicas": 1, # Ночью работает минимум 1 сервер
"max_replicas": 8, # В часы пик поднимаем до 8 серверов
"target_num_ongoing_requests_per_replica": 2, # Если больше 2 запросов в очереди — включаем новый сервер
},
ray_actor_options={"num_gpus": 1},
)
class MusicGenService:
# Инициализация пайплайна (как в примерах выше)
...
Ещё больше полезного и оперативного контента я публикую в своих Telegram-каналах. Присоединяйтесь к обсуждению!
mudi — всё о дистрибуции, работе с площадками и последних новостях. Подписаться →
mishas tips — инсайты, аналитика и разбор трендов всей музыкальной индустрии. Подписаться →
Музыкальный ИИ — слежу за тем, как искусственный интеллект меняет музыку прямо сейчас. Подписаться →